
Les requêtes HTTP
Les requêtes HTTP
-
Objectifs
- Connaitre les requêtes HTTP
- Être capable de différencier les Status des réponses HTTP
-
Définitions
- Une requête HTTP est une demande effectuée par le navigateur WEB (ex: Chrome, Internet Explorer, Firefox, Mozilla, Safari…) au serveur HTTP lorsqu’il souhaite télécharger une page WEB.
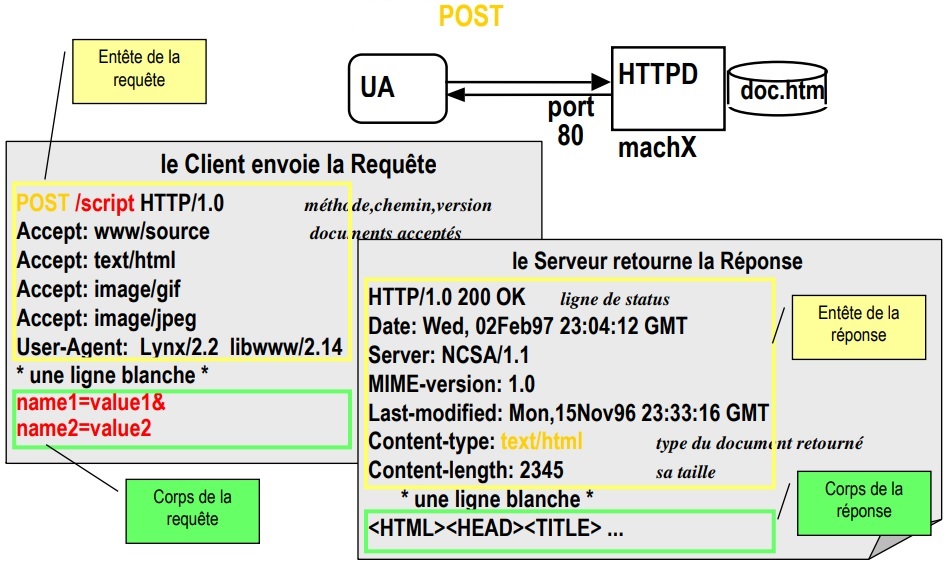
- Une requête HTTP est un ensemble de lignes envoyé au serveur par le navigateur. Elle comprend :
- Une ligne de requête: c’est une ligne précisant le type de document demandé, la méthode qui doit être appliquée, et la version du protocole utilisée. La ligne comprend trois éléments devant être séparés par un espace :
- La méthode
- L’URL
- La version du protocole utilisé par le client (généralement HTTP/1.0)
- Les champs d’en-tête de la requête: il s’agit d’un ensemble de lignes facultatives permettant de donner des informations supplémentaires sur la requête et/ou le client (Navigateur, système d’exploitation, …). Chacune de ces lignes est composée d’un nom qualifiant le type d’en-tête, suivi de deux points (:) et de la valeur de l’en-tête
- Le corps de la requête: c’est un ensemble de lignes optionnelles devant être séparées des lignes précédentes par une ligne vide et permettant par exemple un envoi de données par une commande POST lors de l’envoi de données au serveur par un formulaire
-
Requête HTTP
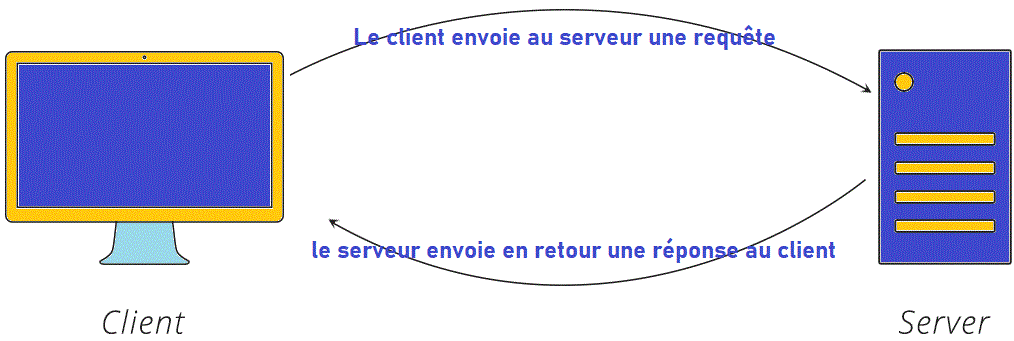
- En HTTP, la communication tourne autour d’un concept appelé requête-réponse. Le client envoie au serveur une requête pour faire quelque chose et le serveur envoie en retour une réponse au client.
- Une requête HTTP est un ensemble de lignes envoyé au serveur par le navigateur. Elle comprend :
- Une ligne de requête: c’est une ligne précisant le type de document demandé, la méthode qui doit être appliquée, et la version du protocole utilisée. La ligne comprend trois éléments devant être séparés par un espace :
- La méthode
- L’URL
- La version du protocole utilisé par le client (généralement HTTP/1.0)
- Les champs d’en-tête de la requête: il s’agit d’un ensemble de lignes facultatives permettant de donner des informations supplémentaires sur la requête et/ou le client (Navigateur, système d’exploitation, …). Chacune de ces lignes est composée d’un nom qualifiant le type d’en-tête, suivi de deux points (:) et de la valeur de l’en-tête
- Le corps de la requête: c’est un ensemble de lignes optionnelles devant être séparées des lignes précédentes par une ligne vide et permettant par exemple un envoi de données par une commande POST lors de l’envoi de données au serveur par un formulaire
-
Réponse HTTP
- Une réponse HTTP est un ensemble de lignes envoyées au navigateur par le serveur. Elle comprend :
- Une ligne de statut: c’est une ligne précisant la version du protocole utilisé et l’état du traitement de la requête à l’aide d’un code et d’un texte explicatif. La ligne comprend trois éléments devant être séparés par un espace :
- La version du protocole utilisé
- Le code de statut
- La signification du code
- Les champs d’en-tête de la réponse: il s’agit d’un ensemble de lignes facultatives permettant de donner des informations supplémentaires sur la réponse et/ou le serveur. Chacune de ces lignes est composée d’un nom qualifiant le type d’en-tête, suivi de deux points (:) et de la valeur de l’en-tête
- Le corps de la réponse: il contient le document demandé
-
Méthodes de requête
- HTTP définit un ensemble de méthodes de requête qui indiquent l’action que l’on souhaite réaliser sur la ressource indiquée.
-
HEAD
- La commande HEAD tente d’accéder à une page web et de renvoyer l’en-tête HTTP.
- L’émission de la commande HEAD permet de vérifier rapidement qu’une page web est accessible.
- La méthode HEAD demande une réponse identique à une requête GET pour laquelle on aura omis le corps de la réponse (on a uniquement l’en-tête).
-
GET
-
GETALL
- La commande GETALL tente d’accéder à la page web et renvoie l’ensemble de la page, notamment l’en-tête HTTP, l’arrière-plan, les images, les applets, les cadres, les fichiers CSS et les scripts. Tout comme les commandes HEAD et GET, cette commande vérifie également qu’une page web est accessible mais étant donné que la commande GETALL renvoie l’ensemble de la page et tous ses fichiers associés, il peut donner une indication plus réaliste de la durée nécessaire pour l’accès à la page. Le moniteur utilise également plusieurs unités d’exécution lors d’une commande GETALL pour une correspondance plus précise du comportement des navigateurs web.
-
POST
- La commande POST tente d’accéder à une page web qui contient un formulaire HTTP et de compléter les zones de ce dernier. Ajoutez un corps de texte pour la requête POST dans l’onglet Corps de texte de la fenêtre de Configuration d’Internet Service Monitoring ou utilisez le groupe @Body dans l’interface de ligne de commande de configuration d’Internet Service Monitoring ou ismbatch. Vous pouvez également utilisez les paramètres FORM. En revanche, vous ne pouvez pas utiliser les paramètres Corps de texte et FORM dans la requête POST.
-
PUT
- La méthode PUT remplace toutes les représentations actuelles de la ressource visée par le contenu de la requête.
-
DELETE
- La méthode DELETE supprime la ressource indiquée.
-
CONNECT
- La méthode CONNECT établit un tunnel vers le serveur identifié par la ressource cible.
-
OPTIONS
- La méthode OPTIONS est utilisée pour décrire les options de communications avec la ressource visée.
-
TRACE
- La méthode TRACE réalise un message de test aller/retour en suivant le chemin de la ressource visée.
-
Liste les Status des réponses HTTP
- le surf commence par une adresse, que vous l’ayez saisie directement, ou quelle soit le résultat d’un moteur de recherche (qui d’ailleurs est lui aussi lancé par une adresse comme par exemple http://www.google.fr), il vous faut toujours une adresse pour aller quelque part. Pour atteindre un serveur http, c’est pareil : on utilise une adresse.
La commande GET tente d’accéder à la page web et de renvoyer l’ensemble de la page, notamment l’en-tête HTTP. Elle ne tente pas de renvoyer les fichiers associés à cette page, tels que les images.
| Code | Message | Signification |
|---|---|---|
1xx |
Information |
|
| 100 | Continue | Attente de la suite de la requête |
| 101 | Switching Protocols | Acceptation du changement de protocole |
| 118 | Connection timed out | délai imparti `à l’opération dépassé |
2xx |
Succès |
|
| 200 | OK | Requête traitée avec succès |
| 201 | Created | Requête traitée avec succès avec création d’un document |
| 202 | Accepted | Requête traitée mais sans garantie de résultat |
| 203 | Non-Authoritative | Information retournée mais générée Information par une source non certifiée |
| 204 | No Content | Requête traitée avec succès mais pas d’information à renvoyer |
| 205 | Reset Content | Requête traitée avec succès , la page courante peut être effacée |
| 206 | Partial Content | Une partie seulement de la Requête a été transmise |
3xx |
Redirection |
|
| 300 | Multiple Choices | L’URI demandée se rapporte à plusieurs ressources |
| 301 | Moved Permanently | Document déplacé de façon permanente |
| 302 | Found | Document déplacé de façon temporaire |
| 303 | See Other | La réponse à cette Requête est ailleurs |
| 304 | Not Modified | Document non modifié depuis la dernière Requête |
| 305 | Use Proxy | La Requête doit ˆêtre réadressée au proxy |
| 307 | Temporary Redirect | La Requête doit ˆêtre redirigée temporairement vers l’URI spécifiée |
| 310 | Too many Redirect | La Requête doit être redirigée de trop nombreuses fois, ou est victime d’une boucle de redirection. |
| 324 | Empty response | Le serveur a mis fin à la connexion sans envoyer de données. |
4xx |
Erreur du client |
|
| 400 | Bad Request | La syntaxe de la Requête est erronée |
| 401 | Unauthorized | Une authentification est nécessaire pour accéder à la ressource |
| 402 | Payment Required | Paiement requis pour accéder à la ressource (non utilisé) |
| 403 | Forbidden | L’authentification est refusée. Contrairement à l’erreur 401, aucune demande d’authentification ne sera faite |
| 404 | Not Found | Ressource non trouvée |
| 405 | Method Not Allowed | Méthode de Requête non autorisée |
| 406 | Not Acceptable | Toutes les réponses possibles seront refusées |
| 407 | Proxy Authentication Required | Accès à la ressource autorisé par identification avec le proxy |
| 408 | Request Time-out | Temps d’attente d’une réponse du serveur écoulé |
| 409 | Conflict | La Requête ne peut pas être traitée à l’état actuel |
| 410 | Gone | La ressource est indisponible et aucune adresse de redirection n’est connue |
| 411 | Length Required | La longueur de la Requête n’a pas été précisée |
| 412 | Precondition Failed | Préconditions envoyées par la Requête non-vérifiées |
| 413 | Request Entity Too Large | Traitement abandonné dû à une Requête trop importante |
| 414 | Request-URI Too Long | URI trop longue |
| 415 | Unsupported | Media Format de Requête non-supporté pour Type une méthode et une ressource données |
| 416 | Requested range unsatisfiable | Champs d’en-tête de Requête incorrect |
| 417 | Expectation failed | Comportement attendu et défini dans l’en-tête de la requête insatisfaisable |
5xx |
Erreur du serveur |
|
| 500 | Internal Server Error | Erreur interne du serveur |
| 501 | Not Implemented | Fonctionnalité réclamée non supportée par le serveur |
| 502 | Bad Gateway or Proxy Error | Mauvaise réponse envoyée à un serveur intermédiaire par un autre serveur |
| 503 | Service Unavailable | Service temporairement indisponible ou en maintenance |
| 504 | Gateway Time-out | Temps d’attente d’une réponse d’un serveur à un serveur intermédiaire écoulé |
| 505 | HTTP Version not supported | Version HTTP non gérée par le serveur |
| 509 | Bandwidth Limit Exceeded | Utilisé par de nombreux serveurs pour indiquer un dépassement de quota |
Source:
- https://www.commentcamarche.net/contents/520-le-protocole-http
- https://www.c2i-revision.fr/complement.php?id_con=131