
- UML est une norme
L’OMG est un organisme à but non lucratif, créé en 1989 à l’initiative de grandes sociétés (HP, Sun, Unisys, American Airlines, Philips…). Aujourd’hui, l’OMG fédère plus de 850 acteurs du monde informatique. Son rôle est de promouvoir des standards qui garantissent l’interopérabilité entre applications orientées objet, développées sur des réseaux hétérogènes.
L’OMG propose notamment l’architecture CORBA (Common Object Request Broker Architecture), un modèle standard pour la construction d’applications à objets distribués (répartis sur un réseau).
CORBA fait partie d’une vision globale de la construction d’applications réparties, appelée OMA (Object Management Architecture) et définie par l’OMG. Sans rentrer dans les détails, on peut résumer cette vision par la volonté de favoriser l’essor industriel des technologies objet, en offrant un ensemble de solutions technologiques non propriétaires, qui suppriment les clivages techniques.
UML a été adopté (normalisé) par l’OMG et intégré à l’OMA, car il participe à cette vision et parce qu’il répond à la « philosophie » OMG.
- UML est un langage de modélisation objet.
Pour conduire une analyse objet cohérente, il ne faut pas directement penser en terme de pointeurs, d’attributs et de tableaux, mais en terme d’association, de propriétés et de cardinalités… Utiliser le langage de programmation comme support de conception ne revient bien souvent qu’à juxtaposer de manière fonctionnelle un ensemble de mécanismes d’implémentation, pour résoudre un problème qui nécessite en réalité une modélisation objet.
L’approche objet nécessite une analyse réfléchie, qui passe par différentes phases exploratoires. Bien que raisonner en terme d’objets semble naturel, l’approche fonctionnelle reste la plus intuitive pour nos esprits cartésiens… Voilà pourquoi il ne faut pas se contenter d’une implémentation objet, mais se discipliner à « penser objet » au cours d’une phase d’analyse
préalable.
Toutes les dérives fonctionnelles de code objet ont pour origine le non respect des concepts de base de l’approche objet (encapsulation…) ou une utilisation détournée de ces concepts (héritage sans classification…). Ces dérives ne sont pas dues à de mauvaises techniques de programmation ; la racine du mal est bien plus profonde : programmer en C++ ou en Java n’implique pas forcément concevoir objet…
Les difficultés de mise en oeuvre d’une approche « réellement objet » ont engendré bien souvent des déceptions, ce qui a longtemps constitué un obstacle important à l’essor des technologies objet. Beaucoup ont cédé au leurre des langages de programmation orientés objet et oublié que le code n’est qu’un « moyen ». Le respect des concepts fondamentaux de l’approche objet prime sur la manière dont on les implémente. Ne penser qu’à travers un langage de programmation objet détourne de l’essentiel.
Pour sortir les technologies objet de cette impasse, l’OMG propose UML.
UML comble une lacune importante des technologies objet. Il permet
d’exprimer et d’élaborer des modèles objet, indépendamment de tout langage de programmation. Il a été pensé pour servir de support à une analyse basée sur les concepts objet.
- UML est un langage formel, défini par un méta-modèle.
modélisation (les concepts véhiculés et manipulés par le langage) et la sémantique de ces éléments (leur définition et le sens de leur utilisation).
En d’autres termes : UML normalise les concepts objet.
Un métamodèle permet de limiter les ambiguïtés et encourage la construction d’outils. Il permet aussi de classer les différents concepts du langage (selon leur niveau d’abstraction ou leur domaine d’application) et expose ainsi clairement sa structure. Enfin, on peut noter que le métamodèle d’UML est lui-même décrit par un méta-métamodèle de manière standardisée, à l’aide de MOF (Meta Object Facility : norme OMG de description des métamodèles).
Véritable clé de voûte de l’OMA, UML est donc un outil indispensable pour tous ceux qui ont compris que programmer objet, c’est d’abord concevoir objet. UML n’est pas à l’origine des concepts objets, mais il en constitue une étape majeure, car il unifie les différentes approches et en donne une définition plus formelle.
- UML est un support de communication
Sa notation graphique permet d’exprimer visuellement une solution objet, ce qui facilite la comparaison et l’évaluation de solutions. L’aspect formel de sa notation limite les ambiguïtés et les incompréhensions. Son indépendance par rapport aux langages de programmation, aux domaines d’application et aux processus, en font un langage universel.
La notation graphique d’UML n’est que le support du langage. La véritable force d’UML, c’est qu’il repose sur un métamodèle. En d’autres termes : la puissance et l’intérêt d’UML, c’est qu’il normalise la sémantique des concepts qu’il véhicule !
Qu’une association d’héritage entre deux classes soit représentée par une flèche terminée par un triangle ou un cercle, n’a que peu d’importance par rapport au sens que cela donne à votre modèle. La notation graphique est essentiellement guidée par des considérations esthétiques, même si elle a été pensée dans ses moindres détails.
Par contre, utiliser une relation d’héritage, reflète l’intention de donner à votre modèle un sens particulier. Un « bon » langage de modélisation doit permettre à n’importe qui de déchiffrer cette intention de manière non équivoque. Il est donc primordial de s’accorder sur la sémantique des éléments de modélisation, bien avant de s’intéresser à la manière de les représenter.
Le métamodèle UML apporte une solution à ce problème fondamental.
UML est donc bien plus qu’un simple outil qui permet de « dessiner » des
représentations mentales… Il permet de parler un langage commun, normalisé mais accessible, car visuel.
- UML est un cadre méthodologique pour une analyse objet
Combinés, les différents types de diagrammes UML offrent une vue complète des aspects statiques et dynamiques d’un système. Les diagrammes permettent donc d’inspecter un modèle selon différentes perspectives et guident l’utilisation des éléments de modélisation (les concepts objet), car ils possèdent une structure.
Une caractéristique importante des diagrammes UML, est qu’ils supportent l’abstraction. Cela permet de mieux contrôler la complexité dans l’expression et l’élaboration des solutions objet.
UML opte en effet pour l’élaboration des modèles, plutôt que pour une approche qui impose une barrière stricte entre analyse et conception. Les modèles d’analyse et de conception ne diffèrent que par leur niveau de détail, il n’y a pas de différence dans les concepts utilisés. UML n’introduit pas d’éléments de modélisation propres à une activité (analyse, conception…) ; le langage reste le même à tous les niveaux d’abstraction.
Cette approche simplificatrice facilite le passage entre les niveaux d’abstraction.
L’élaboration encourage une approche non linéaire, les « retours en arrière » entre niveaux d’abstraction différents sont facilités et la traçabilité entre modèles de niveaux différents est assurée par l’unicité du langage.
UML favorise donc le prototypage, et c’est là une de ses forces. En effet, modéliser une application n’est pas une activité linéaire. Il s’agit d’une tâche très complexe, qui nécessite une approche itérative, car il est plus efficace de construire et valider par étapes, ce qui est difficile à cerner et maîtriser.
UML permet donc non seulement de représenter et de manipuler les concepts objet, il sous-entend une démarche d’analyse qui permet de concevoir une solution objet de manière itérative, grâce aux diagrammes, qui supportent l’abstraction.
- UML n’est pas une méthode
Une méthode propose aussi un processus, qui régit notamment l’enchaînement des activités de production d’une entreprise. Or UML n’a pas été pensé pour régir les activités de l’entreprise.
Les auteurs d’UML sont tout à fait conscients de l’importance du processus, mais ce sujet a été intentionnellement exclu des travaux de l’OMG. Comment prendre en compte toutes les organisations et cultures d’entreprises ? Un processus est adapté (donc très lié) au domaine d’activité de l’entreprise ; même s’il constitue un cadre général, il faut l’adapter au contexte de l’entreprise. Bref, améliorer un processus est une discipline à part entière, c’est un objectif qui dépasse très largement le cadre de l’OMA.
Cependant, même si pour l’OMG, l’acceptabilité industrielle de la modélisation objet passe d’abord par la disponibilité d’un langage d’analyse objet performant et standard, les auteurs d’UML préconisent d’utiliser une démarche :
guidée par les besoins des utilisateurs du système,
centrée sur l’architecture logicielle,
itérative et incrémentale.
D’après les auteurs d’UML, un processus de développement qui possède ces qualités fondamentales « devrait » favoriser la réussite d’un projet.
Une source fréquente de malentendus sur UML a pour origine la faculté d’UML de modéliser un processus, pour le documenter et l’optimiser par exemple. En fin de compte, qu’est-ce qu’un processus ? Un ensemble d’activités coordonnées et régulées, en partie ordonnées, dont le but est de créer un produit (matériel ou intellectuel). UML permet tout à fait de modéliser les activités (c’est-à-dire la dynamique) d’un processus, de décrire le rôle des acteurs du processus, la structure des éléments manipulés et produits, etc…
Une extension d’UML (« UML extension for business modeling ») propose d’ailleurs un certain nombre de stéréotypes standards (extensions du métamodèle) pour mieux décrire les processus.
Le RUP (« Rational Unified Process »), processus de développement « clé en main », proposé par Rational Software, est lui aussi modélisé (documenté) avec UML. Il offre un cadre méthodologique générique qui repose sur UML et la suite d’outils Rational.
- Conclusion
Intégrer UML par étapes dans un processus, de manière pragmatique, est tout à fait possible. La faculté d’UML de se fondre dans le processus courant, tout en véhiculant une démarche méthodologique, facilite son intégration et limite de nombreux risques (rejet des utilisateurs, coûts…).
Intégrer UML dans un processus ne signifie donc pas révolutionner ses méthodes de travail, mais cela devrait être l’occasion de se remettre en question.
[/stm_course_lesson][stm_course_lesson icon= »fa-icon-stm_icon_book_stack » title= »Le contexte d’apparition d’UML : L’approche fonctionnelle »]
- L’approche fonctionnelle
La découpe fonctionnelle d’un problème (sur laquelle reposent les langages de programmation structurée) consiste à découper le problème en blocs indépendants. En ce sens, elle présente un caractère intuitif fort.
La réutilisabilité du code
Le découpage en blocs fonctionnels n’a malheureusement pas que des avantages. Les fonctions sont devenues interdépendantes : une simple mise à jour du logiciel à un point donné, peut impacter en cascade une multitude d’autres fonctions. On peut minorer cet impact, pour peu qu’on utilise des fonctions plus génériques et des structures de données ouvertes. Mais respecter ces contraintes rend l’écriture du logiciel et sa maintenance plus complexe.
En cas d’évolution majeure du logiciel (passage de la gestion d’une bibliothèque à celle d’une médiathèque par exemple), le scénario est encore pire. Même si la structure générale du logiciel reste valide, la multiplication des points de maintenance, engendrée par le chaînage des fonctions, rend l’adaptation très laborieuse. Le logiciel doit être retouché dans sa globalité :
- On a de nouvelles données à gérer (ex : DVD)
- Les traitements évoluent : l’affichage sera différent selon le type (livre, CD, DVD …)
Examinons le problème de l’évolution de code fonctionnel plus en détail…
Faire évoluer une application de gestion de bibliothèque pour gérer une médiathèque, afin de prendre en compte de nouveaux types d’ouvrages (cassettes vidéo, CD-ROM, etc.…), nécessite :
- De faire évoluer les structures de données qui sont manipulées par les fonctions,
- D’adapter les traitements, qui ne manipulaient à l’origine qu’un seul type de document (des livres).
Il faudra donc modifier toutes les portions de code qui utilisent la base documentaire, pour gérer les données et les actions propres aux différents types de documents.
Il faudra par exemple modifier la fonction qui réalise l’édition des « lettres de rappel » (une lettre de rappel est une mise en demeure, qu’on envoie automatiquement aux personnes qui tardent à rendre un ouvrage emprunté). Si l’on désire que le délai avant rappel varie selon le type de document emprunté, il faut prévoir une règle de calcul pour chaque type de document.
En fait, c’est la quasi-totalité de l’application qui devra être adaptée, pour gérer les nouvelles données et réaliser les traitements correspondants. Et cela, à chaque fois qu’on décidera de gérer un nouveau type de document !
1ère amélioration : rassembler les valeurs qui caractérisent un type, dans le type
Une solution relativement élégante à la multiplication des branches conditionnelles et des redondances dans le code (conséquence logique d’une trop grande ouverture des données), consiste tout simplement à centraliser dans les structures de données, les valeurs qui leurs sont propres.
Par exemple, le délai avant rappel peut être défini pour chaque type de document. Cela permet donc de créer une fonction plus générique qui s’applique à tous les types de documents.
2ème amélioration : centraliser les traitements associés à un type, auprès du type
Pourquoi ne pas aussi rassembler dans une même unité physique les types de données et tous les traitements associés ?
Que se passerait-il par exemple si l’on centralisait dans un même fichier, la structure de données qui décrit les documents et la fonction de calcul du délai avant rappel ? Cela nous permettrait de retrouver immédiatement la partie de code qui est chargée de calculer le délai avant rappel d’un document, puisqu’elle se trouve au plus près de la structure de données concernée.
Ainsi, si notre médiathèque devait gérer un nouveau type d’ouvrage, il suffirait de modifier une seule fonction (qu’on sait retrouver instantanément), pour assurer la prise en compte de ce nouveau type de document dans le calcul du délai avant rappel. Plus besoin de fouiller partout dans le code…
Écrit en ces termes, le logiciel serait plus facile à maintenir et bien plus lisible. Le stockage et le calcul du délai avant rappel des documents, serait désormais assuré par une seule et unique unité physique (quelques lignes de code, rapidement identifiables).
Pour accéder à la caractéristique « délai avant rappel » d’un document, il suffit de récupérer la valeur correspondante parmi les champs qui décrivent le document. Pour assurer la prise en compte d’un nouveau type de document dans le calcul du délai avant rappel, il suffit de modifier une seule fonction, située au même endroit que la structure de données qui décrit les documents.
| Document |
| Code document
Nom document Type document |
| Calculer date rappel |
Centraliser les données d’un type et les traitements associés, dans une même unité physique, permet de limiter les points de maintenance dans le code et facilite l’accès à l’information en cas d’évolution du logiciel.[/stm_course_lesson][stm_course_lesson icon= »fa-icon-stm_icon_book_stack » title= »Le contexte d’apparition d’UML : L’approche objet »]
- Le concept d’objet
Les modifications qui ont été apportées au logiciel de gestion de médiathèque, nous ont amené à transformer ce qui était à l’origine une structure de données, manipulée par des fonctions, en une entité autonome, qui regroupe un ensemble de propriétés cohérentes et de traitements associés. Une telle entité s’appelle… un objet et constitue le concept fondateur de l’approche du même nom.
Un objet est une entité aux frontières précises qui possède une identité (un nom). Un ensemble d’attributs caractérise l’état de l’objet.
Un ensemble d’opérations (méthodes) en définissent le comportement. Un objet est une instance de classe (une occurrence d’un type abstrait).
Une classe est un type de données abstrait, caractérisé par des propriétés (attributs et méthodes) communes à des objets et permettant de créer des objets possédant ces propriétés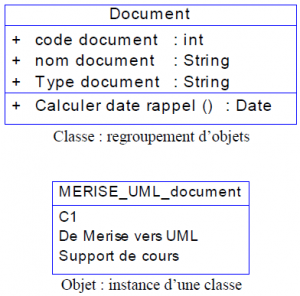
- Les autres concepts importants de l’approche objet.
- l’encapsulation
L’encapsulation consiste à masquer les détails d’implémentation d’un objet, en définissant une interface.
L’interface est la vue externe d’un objet, elle définit les services accessibles (offerts) aux utilisateurs de l’objet.
L’encapsulation facilite l’évolution d’une application car elle stabilise l’utilisation des objets : on peut modifier l’implémentation des attributs d’un objet sans modifier son interface.
L’encapsulation garantit l’intégrité des données, car elle permet d’interdire l’accès direct aux attributs des objets.
- l’héritage
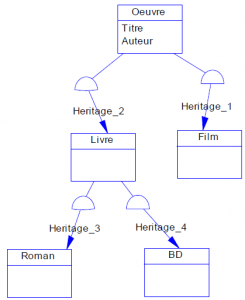
L’héritage est un mécanisme de transmission des propriétés d’une classe (ses attributs et méthodes) vers une sous-classe.
Une classe peut être spécialisée en d’autres classes, afin d’y ajouter des caractéristiques spécifiques ou d’en adapter certaines.
Plusieurs classes peuvent être généralisées en une classe qui les factorise, afin de regrouper les caractéristiques communes d’un ensemble de classes.
La spécialisation et la généralisation permettent de construire des hiérarchies de classes. L’héritage peut être simple ou multiple.
L’héritage évite la duplication et encourage la réutilisation.
- le polymorphisme
Le polymorphisme représente la faculté d’une même opération de s’exécuter différemment suivant le contexte de la classe où elle se trouve.
Ainsi, une opération définie dans une superclasse peut s’exécuter de façon différente selon la sous-classe où elle est héritée.
Ex : exécution d’une opération de calcul des salaires dans 2 sous-classes spécialisées : une pour les cadres, l’autre pour les non-cadres.
Le polymorphisme augmente la généricité du code.
- l’agrégation
Il s’agit d’une relation entre deux classes, spécifiant que les objets d’une classe sont des composants de l’autre classe.
Une relation d’agrégation permet donc de définir des objets composés d’autres objets. L’agrégation permet d’assembler des objets de base, afin de construire des objets plus complexes.
- Historique de l’approche objet
Les concepts objet sont stables et éprouvés (issus du terrain) :
– Simula, 1er langage de programmation à implémenter le concept de type abstrait (à l’aide de classes), date de 1967 !
– En 1976 déjà, Smalltalk implémente les concepts fondateurs de l’approche objet (encapsulation, agrégation, héritage) à l’aide de :
- Classes
- Associationsentre classes
- Hiérarchies de classes
- Messages entre objets
– Le 1er compilateur C++ date de 1980, et C++ est normalisé par l’ANSI.
– De nombreux langages orientés objets académiques ont étayés les concepts objets : Eiffel, Objective C, Loops…
Les concepts objet sont anciens, mais ils n’ont jamais été autant d’actualité :
– L’approche fonctionnelle n’est pas adaptée au développement d’applications qui évoluent sans cesse et dont la complexité croit continuellement.
– L’approche objet a été inventée pour faciliter l’évolution d’applications complexes.
De nos jours, les outils orientés objet sont fiables et performants
– Les compilateurs C++ produisent un code robuste et optimisé.
– De très nombreux outils facilitent le développement d’applications C++ :
- Bibliothèques (STL, USL, Rogue Wave, MFC…)
- Environnements de développement intégrés (Developper Studio,Sniff+…)
- Outils de qu’altimétries et de tests (Cantata++, Insure++, Logiscope…)
- Bases de données orientées objet (O2, ObjectStore, Versant…)
- Inconvénients de l’approche objet
L’approche objet est moins intuitive que l’approche fonctionnelle.
L’application des concepts objets nécessite une grande rigueur : le vocabulaire est précis (risques d’ambiguïtés, d’incompréhensions).
- Solutions pour remédier aux inconvénients de l’approche objet
Il faut bénéficier d’un langage pour exprimer les concepts objet qu’on utilise, afin de pouvoir :
-représenter des concepts abstraits (graphiquement par exemple).
-limiter les ambiguïtés (parler un langage commun).
-faciliter l’analyse (simplifier la comparaison et l’évaluation de solutions).
Il faut également une démarche d’analyse et de conception objet, pour :
-ne pas effectuer une analyse fonctionnelle et se contenter d’une implémentation objet, mais penser objet dès le départ.
-définir les vues qui permettent de couvrir tous les aspects d’un système, avec des concepts objets.[/stm_course_lesson][stm_course_lesson icon= »fa-icon-stm_icon_book_stack » title= »Historique des méthodes d’analyse »]Les premières méthodes d’analyse (années 70)
Découpe cartésienne (fonctionnelle et hiérarchique) d’un système.
L’approche systémique (années 80)
Modélisation des données + modélisation des traitements (Merise …).
L’émergence des méthodes objet (1990-1995)
Prise de conscience de l’importance d’une méthode spécifiquement objet :
-comment structurer un système sans centrer l’analyse uniquement sur les données ou uniquement sur les traitements (mais sur les deux) ?
-Plus de 50 méthodes objet sont apparues durant cette période (Booch, Classe- Relation, Fusion, HOOD, OMT, OOA, OOD, OOM, OOSE…) !
-Aucun méthode ne s’est réellement imposée.
Les premiers consensus (1995)
-OMT (James Rumbaugh) : vues statiques, dynamiques et fonctionnelles d’un système
o issue du centre de R&D de General Electric.
o Notation graphique riche et lisible.
-OOD (Grady Booch) : vues logiques et physiques du système
o Définie pour le DOD, afin de rationaliser de développement d’applications ADA, puis C++.
o Ne couvre pas la phase d’analyse dans ses 1ères versions (préconise SADT).
o Introduit le concept de package (élément d’organisation des modèles).
-OOSE (Ivar Jacobson) : couvre tout le cycle de développement
o Issue d’un centre de développement d’Ericsson, en Suède.
o La méthodologie repose sur l’analyse des besoins des utilisateurs.
L’unification et la normalisation des méthodes (1995-1997)
En octobre 1994, G. Booch (père fondateur de la méthode Booch) et J. Rumbaugh (principal auteur de la méthode OMT) ont décidé de travailler ensemble pour unifier leurs méthodes au sein de la société Rational Software. Un an après, I . Jacobson (auteur de la méthode OOSE et des cas d’utilisation) a rejoint Rational Software pour travailler sur l’unification. Unified Modified Language (UML) est né.
Les travaux sur ce langage ont continué avec son adoption par de grands acteurs industriels comme HP, Microsoft, Oracle ou Unisys. Ce travail a abouti en 1997 à UML 1.0. Le langage a été soumis par Rational Software et ses partenaires à l’OMG comme réponse à un appel d’offres sur la standardisation des langages de modélisation.
L’appel d’offres de l’OMG a recueilli un avis favorable, puisque 6 réponses concurrentes sont parvenues à l’OMG. IBM et Object Time (méthode ROOM pour les systèmes temps réel réactifs) ont décidé de rejoindre l’équipe UML ; leur proposition était en fait une extension d’UML 1.0.
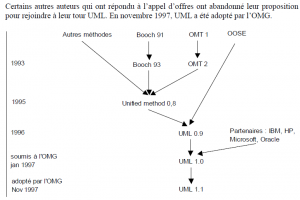
UML est donc le résultat d’un large consensus et tient compte des dernières avancées en matière de modélisation et de développement logiciel.
L’OMG RTF (nombreux acteurs industriels) centralise et normalise les évolutions d’UML au niveau international et de nombreux groupes d’utilisateurs UML favorisent le partage des expériences.[/stm_course_lesson][stm_course_lesson icon= »fa-icon-stm_icon_book_stack » title= »Cadre d’utilisation d’UML »]UML n’est pas une méthode ou un processus
Si l’on parle de méthode objet pour UML, c’est par abus de langage.
Ce constat vaut aussi pour OMT ou d’autres techniques / langages de modélisation.
Une méthode propose aussi un processus, qui régit notamment l’enchaînement des activités de production d’une entreprise. Or, UML a été pensé pour permettre de modéliser les activités de l’entreprise, pas pour les régir.
Des méthodes orientées objet les plus connues, seules les méthodes OOSE et BOOCH incluent cet aspect « processus » de manière explicite et formelle. Ces 2 auteurs se sont d’ailleurs toujours démarqués des autres sur ce point.
Par leur nature, les processus doivent être adaptés aux organisations, à leurs domaines d’activité, à leur culture …
De ce fait, ni la normalisation ni la standardisation d’un processus de développement logiciel ne peut faire l’objet d’un consensus international suffisant pour aboutir à un standard acceptable et utilisable.
UML est un langage de modélisation
UML est un langage de modélisation au sens de la théorie des langages. Il contient de ce fait les éléments constitutifs de tout langage, à savoir : des concepts, une syntaxe et une sémantique.
De plus, UML a choisi une notation supplémentaire : il s’agit d’une forme visuelle fondée sur des diagrammes. Si l’unification d’une notation est secondaire par rapports aux éléments constituant le langage, elle reste cependant primordiale pour la communication et la compréhension.
UML décrit un méta modèle
UML est fondé sur un méta modèle, qui définit :
-les éléments de modélisation (les concepts manipulés par le langage),
-la sémantique de ces éléments (leur définition et le sens de leur utilisation).
Un méta modèle est une description très formelle de tous les concepts d’un langage. Il limite les ambiguïtés et encourage la construction d’outils.
Le méta modèle d’UML permet de classer les concepts du langage (selon leur niveau d’abstraction ou domaine d’application) et expose sa structure.
Le méta modèle UML est lui-même décrit par un méta-méta modèle (OMG-MOF).
UML propose aussi une notation, qui permet de représenter graphiquement les éléments de modélisation du méta modèle.
Cette notation graphique est le support du langage UML.
UML offre :
-différentes vues (perspectives) complémentaires d’un système, qui guident l’utilisation des concept objets
-plusieurs niveaux d’abstraction, qui permettent de mieux contrôler la complexité dans l’expression des solutions objets.
UML est un support de communication
Sa notation graphique permet d’exprimer visuellement une solution objet. L’aspect formel de sa notation limite les ambiguïtés et les incompréhensions. Son aspect visuel facilite la comparaison et l’évaluation de solutions.
Son indépendance (par rapport aux langages d’implémentation, domaine d’application, processus…) en fait un langage universel.[/stm_course_lesson][stm_course_lesson icon= »fa-icon-stm_icon_book_stack » title= »Points forts d’UML »]UML est un langage formel et normalisé
Il permet ainsi :
-un gain de précision
-un gage de stabilité
-l’utilisation d’outils
UML est un support de communication performant
Il cadre l’analyse et facilite la compréhension de représentations abstraites complexes. Son caractère polyvalent et sa souplesse en font un langage universel.[/stm_course_lesson][stm_course_lesson icon= »fa-icon-stm_icon_book_stack » title= »Points faibles d’UML »]
- La mise en pratique d’UML nécessite un apprentissage et passe par une période d’adaptation.
Même si l’Espéranto est une utopie, la nécessité de s’accorder sur des modes d’expression communs est vitale en informatique. UML n ‘est pas à l’origine des concepts objets, mais en constitue une étape majeure, car il unifie les différentes approches et en donne une définition plus formelle.
- Le processus (non couvert par UML) est une autre clé de la réussite d’un projet.
L’intégration d’UML dans un processus n’est pas triviale et améliorer un processus est un tâche complexe et longue.[/stm_course_lesson][/stm_course_lessons]